Don’t be afraid – Some clarification to common misunderstandings
Since version 3.1, Apache Lucene and Solr use MMapDirectory by default on 64bit Windows and Solaris systems; since version 3.3 also for 64bit Linux systems. This change lead to some confusion among Lucene and Solr users, because suddenly their systems started to behave differently than in previous versions. On the Lucene and Solr mailing lists a lot of posts arrived from users asking why their Java installation is suddenly consuming three times their physical memory or system administrators complaining about heavy resource usage. Also consultants were starting to tell people that they should not use MMapDirectory and change their solrconfig.xml to work instead with slow SimpleFSDirectory or NIOFSDirectory (which is much slower on Windows, caused by a JVM bug #6265734). From the point of view of the Lucene committers, who carefully decided that using MMapDirectory is the best for those platforms, this is rather annoying, because they know, that Lucene/Solr can work with much better performance than before. Common misinformation about the background of this change causes suboptimal installations of this great search engine everywhere.
In this blog post, I will try to explain the basic operating system facts regarding virtual memory handling in the kernel and how this can be used to largely improve performance of Lucene (“VIRTUAL MEMORY for DUMMIES”). It will also clarify why the blog and mailing list posts done by various people are wrong and contradict the purpose of MMapDirectory. In the second part I will show you some configuration details and settings you should take care of to prevent errors like “mmap failed” and suboptimal performance because of stupid Java heap allocation.
In this blog post, I will try to explain the basic operating system facts regarding virtual memory handling in the kernel and how this can be used to largely improve performance of Lucene (“VIRTUAL MEMORY for DUMMIES”). It will also clarify why the blog and mailing list posts done by various people are wrong and contradict the purpose of MMapDirectory. In the second part I will show you some configuration details and settings you should take care of to prevent errors like “mmap failed” and suboptimal performance because of stupid Java heap allocation.
Virtual Memory[1]
Let’s start with your operating system’s kernel: The naive approach to do I/O in software is the way, you have done this since the 1970s – the pattern is simple: whenever you have to work with data on disk, you execute a syscall to your operating system kernel, passing a pointer to some buffer (e.g. a byte[] array in Java) and transfer some bytes from/to disk. After that you parse the buffer contents and do your program logic. If you don’t want to do too many syscalls (because those may cost a lot processing power), you generally use large buffers in your software, so synchronizing the data in the buffer with your disk needs to be done less often. This is one reason, why some people suggest to load the whole Lucene index into Java heap memory (e.g., by using RAMDirectory).
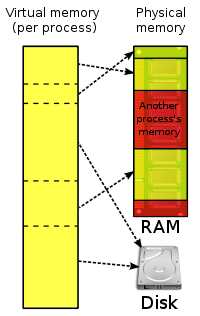
But all modern operating systems like Linux, Windows (NT+), MacOS X, or Solaris provide a much better approach to do this 1970s style of code by using their sophisticated file system caches and memory management features. A feature called “virtual memory” is a good alternative to handle very large and space intensive data structures like a Lucene index. Virtual memory is an integral part of a computer architecture; implementations require hardware support, typically in the form of a memory management unit (MMU) built into the CPU. The way how it works is very simple: Every process gets his own virtual address space where all libraries, heap and stack space is mapped into. This address space in most cases also start at offset zero, which simplifies loading the program code because no relocation of address pointers needs to be done. Every process sees a large unfragmented linear address space it can work on. It is called “virtual memory” because this address space has nothing to do with physical memory, it just looks like so to the process. Software can then access this large address space as if it were real memory without knowing that there are other processes also consuming memory and having their own virtual address space. The underlying operating system works together with the MMU (memory management unit) in the CPU to map those virtual addresses to real memory once they are accessed for the first time. This is done using so called page tables, which are backed by TLBs located in the MMU hardware (translation lookaside buffers, they cache frequently accessed pages). By this, the operating system is able to distribute all running processes’ memory requirements to the real available memory, completely transparent to the running programs.
But all modern operating systems like Linux, Windows (NT+), MacOS X, or Solaris provide a much better approach to do this 1970s style of code by using their sophisticated file system caches and memory management features. A feature called “virtual memory” is a good alternative to handle very large and space intensive data structures like a Lucene index. Virtual memory is an integral part of a computer architecture; implementations require hardware support, typically in the form of a memory management unit (MMU) built into the CPU. The way how it works is very simple: Every process gets his own virtual address space where all libraries, heap and stack space is mapped into. This address space in most cases also start at offset zero, which simplifies loading the program code because no relocation of address pointers needs to be done. Every process sees a large unfragmented linear address space it can work on. It is called “virtual memory” because this address space has nothing to do with physical memory, it just looks like so to the process. Software can then access this large address space as if it were real memory without knowing that there are other processes also consuming memory and having their own virtual address space. The underlying operating system works together with the MMU (memory management unit) in the CPU to map those virtual addresses to real memory once they are accessed for the first time. This is done using so called page tables, which are backed by TLBs located in the MMU hardware (translation lookaside buffers, they cache frequently accessed pages). By this, the operating system is able to distribute all running processes’ memory requirements to the real available memory, completely transparent to the running programs.
Schematic drawing of virtual memory
(image from Wikipedia [1], http://en.wikipedia.org/wiki/File:Virtual_memory.svg, licensed by CC BY-SA 3.0)
{kind=link}
By using this virtualization, there is one more thing, the operating system can do: If there is not enough physical memory, it can decide to “swap out” pages no longer used by the processes, freeing physical memory for other processes or caching more important file system operations. Once a process tries to access a virtual address, which was paged out, it is reloaded to main memory and made available to the process. The process does not have to do anything, it is completely transparent. This is a good thing to applications because they don’t need to know anything about the amount of memory available; but also leads to problems for very memory intensive applications like Lucene.
Lucene & Virtual Memory
Let’s take the example of loading the whole index or large parts of it into “memory” (we already know, it is only virtual memory). If we allocate a RAMDirectory and load all index files into it, we are working against the operating system: The operating system tries to optimize disk accesses, so it caches already all disk I/O in physical memory. We copy all these cache contents into our own virtual address space, consuming horrible amounts of physical memory (and we must wait for the copy operation to take place!). As physical memory is limited, the operating system may, of course, decide to swap out our large RAMDirectory and where does it land? – On disk again (in the OS swap file)! In fact, we are fighting against our O/S kernel who pages out all stuff we loaded from disk [2]. So RAMDirectory is not a good idea to optimize index loading times! Additionally, RAMDirectory has also more problems related to garbage collection and concurrency. Because the data residing in swap space, Java’s garbage collector has a hard job to free the memory in its own heap management. This leads to high disk I/O, slow index access times, and minute-long latency in your searching code caused by the garbage collector driving crazy.
On the other hand, if we don’t use RAMDirectory to buffer our index and use NIOFSDirectory or SimpleFSDirectory, we have to pay another price: Our code has to do a lot of syscalls to the O/S kernel to copy blocks of data between the disk or filesystem cache and our buffers residing in Java heap. This needs to be done on every search request, over and over again.
On the other hand, if we don’t use RAMDirectory to buffer our index and use NIOFSDirectory or SimpleFSDirectory, we have to pay another price: Our code has to do a lot of syscalls to the O/S kernel to copy blocks of data between the disk or filesystem cache and our buffers residing in Java heap. This needs to be done on every search request, over and over again.
Memory Mapping Files
The solution to the above issues is MMapDirectory, which uses virtual memory and a kernel feature called “mmap” [3] to access the disk files.
Basically mmap does the same like handling the Lucene index as a swap file. The mmap() syscall tells the O/S kernel to virtually map our whole index files into the previously described virtual address space, and make them look like RAM available to our Lucene process. We can then access our index file on disk just like it would be a large byte[] array (in Java this is encapsulated by a ByteBuffer interface to make it safe for use by Java code). If we access this virtual address space from the Lucene code we don’t need to do any syscalls, the processor’s MMU and TLB handles all the mapping for us. If the data is only on disk, the MMU will cause an interrupt and the O/S kernel will load the data into file system cache. If it is already in cache, MMU/TLB map it directly to the physical memory in file system cache. It is now just a native memory access, nothing more! We don’t have to take care of paging in/out of buffers, all this is managed by the O/S kernel. Furthermore, we have no concurrency issue, the only overhead over a standard byte[] array is some wrapping caused by Java’s ByteBuffer interface (it is still slower than a real byte[] array, but that is the only way to use mmap from Java and is much faster than all other directory implementations shipped with Lucene). We also waste no physical memory, as we operate directly on the O/S cache, avoiding all Java GC issues described before.
What does this all mean to our Lucene/Solr application?
In our previous approaches, we were relying on using a syscall to copy the data between the file system cache and our local Java heap. How about directly accessing the file system cache? This is what mmap does!
Basically mmap does the same like handling the Lucene index as a swap file. The mmap() syscall tells the O/S kernel to virtually map our whole index files into the previously described virtual address space, and make them look like RAM available to our Lucene process. We can then access our index file on disk just like it would be a large byte[] array (in Java this is encapsulated by a ByteBuffer interface to make it safe for use by Java code). If we access this virtual address space from the Lucene code we don’t need to do any syscalls, the processor’s MMU and TLB handles all the mapping for us. If the data is only on disk, the MMU will cause an interrupt and the O/S kernel will load the data into file system cache. If it is already in cache, MMU/TLB map it directly to the physical memory in file system cache. It is now just a native memory access, nothing more! We don’t have to take care of paging in/out of buffers, all this is managed by the O/S kernel. Furthermore, we have no concurrency issue, the only overhead over a standard byte[] array is some wrapping caused by Java’s ByteBuffer interface (it is still slower than a real byte[] array, but that is the only way to use mmap from Java and is much faster than all other directory implementations shipped with Lucene). We also waste no physical memory, as we operate directly on the O/S cache, avoiding all Java GC issues described before.
What does this all mean to our Lucene/Solr application?
- We should not work against the operating system anymore, so allocate as less as possible heap space (-Xmx Java option). Remember, our index accesses rely on passed directly to O/S cache! This is also very friendly to the Java garbage collector.
- Free as much as possible physical memory to be available for the O/S kernel as file system cache. Remember, our Lucene code works directly on it, so reducing the number of paging/swapping between disk and memory. Allocating too much heap to our Lucene application hurts performance! Lucene does not require it with MMapDirectory.
Why does this only work as expected on operating systems and Java virtual machines with 64bit?
One limitation of 32bit platforms is the size of pointers, they can refer to any address within 0 and 232-1, which is 4 Gigabytes. Most operating systems limit that address space to 3 Gigabytes because the remaining address space is reserved for use by device hardware and similar things. This means the overall linear address space provided to any process is limited to 3 Gigabytes, so you cannot map any file larger than that into this “small” address space to be available as big byte[] array. And when you mapped that one large file, there is no virtual space (address like “house number”) available anymore. As physical memory sizes in current systems already have gone beyond that size, there is no address space available to make use for mapping files without wasting resources (in our case “address space”, not physical memory!).
On 64bit platforms this is different: 264-1 is a very large number, a number in excess of 18 quintillion bytes, so there is no real limit in address space. Unfortunately, most hardware (the MMU, CPU’s bus system) and operating systems are limiting this address space to 47 bits for user mode applications (Windows: 43 bits) [4]. But there is still much of addressing space available to map terabytes of data.
On 64bit platforms this is different: 264-1 is a very large number, a number in excess of 18 quintillion bytes, so there is no real limit in address space. Unfortunately, most hardware (the MMU, CPU’s bus system) and operating systems are limiting this address space to 47 bits for user mode applications (Windows: 43 bits) [4]. But there is still much of addressing space available to map terabytes of data.
Common misunderstandings
If you have read carefully what I have told you about virtual memory, you can easily verify that the following is true:
- MMapDirectory does not consume additional memory and the size of mapped index files is not limited by the physical memory available on your server. By mmap() files, we only reserve address space not memory! Remember, address space on 64bit platforms is for free!
- MMapDirectory will not load the whole index into physical memory. Why should it do this? We just ask the operating system to map the file into address space for easy access, by no means we are requesting more. Java and the O/S optionally provide the option to try loading the whole file into RAM (if enough is available), but Lucene does not use that option (we may add this possibility in a later version).
- MMapDirectory does not overload the server when “top” reports horrible amounts of memory. “top” (on Linux) has three columns related to memory: “VIRT”, “RES”, and “SHR”. The first one (VIRT, virtual) is reporting allocated virtual address space (and that one is for free on 64 bit platforms!). This number can be multiple times of your index size or physical memory when merges are running in IndexWriter. If you have only one IndexReader open it should be approximately equal to allocated heap space (-Xmx) plus index size. It does not show physical memory used by the process. The second column (RES, resident) memory shows how much (physical) memory the process allocated for operating and should be in the size of your Java heap space. The last column (SHR, shared) shows how much of the allocated virtual address space is shared with other processes. If you have several Java applications using MMapDirectory to access the same index, you will see this number going up. Generally, you will see the space needed by shared system libraries, JAR files, and the process executable itself (which are also mmapped).
How to configure my operating system and Java VM to make optimal use of MMapDirectory?
First of all, default settings in Linux distributions and Solaris/Windows are perfectly fine. But there are some paranoid system administrators around, that want to control everything (with lack of understanding). Those limit the maximum amount of virtual address space that can be allocated by applications. So please check that “ulimit -v” and “ulimit -m” both report “unlimited”, otherwise it may happen that MMapDirectory reports “mmap failed” while opening your index. If this error still happens on systems with lot’s of very large indexes, each of those with many segments, you may need to tune your kernel parameters in /etc/sysctl.conf: The default value of vm.max_map_count is 65530, you may need to raise it. I think, for Windows and Solaris systems there are similar settings available, but it is up to the reader to find out how to use them.
For configuring your Java VM, you should rethink your memory requirements: Give only the really needed amount of heap space and leave as much as possible to the O/S. As a rule of thumb: Don’t use more than ¼ of your physical memory as heap space for Java running Lucene/Solr, keep the remaining memory free for the operating system cache. If you have more applications running on your server, adjust accordingly. As usual the more physical memory the better, but you don’t need as much physical memory as your index size. The kernel does a good job in paging in frequently used pages from your index.
A good possibility to check that you have configured your system optimally is by looking at both "top" (and correctly interpreting it, see above) and the similar command "iotop" (can be installed, e.g., on Ubuntu Linux by "apt-get install iotop"). If your system does lots of swap in/swap out for the Lucene process, reduce heap size, you possibly used too much. If you see lot's of disk I/O, buy more RUM (Simon Willnauer) so mmapped files don't need to be paged in/out all the time, and finally: buy SSDs.
Happy mmapping!
For configuring your Java VM, you should rethink your memory requirements: Give only the really needed amount of heap space and leave as much as possible to the O/S. As a rule of thumb: Don’t use more than ¼ of your physical memory as heap space for Java running Lucene/Solr, keep the remaining memory free for the operating system cache. If you have more applications running on your server, adjust accordingly. As usual the more physical memory the better, but you don’t need as much physical memory as your index size. The kernel does a good job in paging in frequently used pages from your index.
A good possibility to check that you have configured your system optimally is by looking at both "top" (and correctly interpreting it, see above) and the similar command "iotop" (can be installed, e.g., on Ubuntu Linux by "apt-get install iotop"). If your system does lots of swap in/swap out for the Lucene process, reduce heap size, you possibly used too much. If you see lot's of disk I/O, buy more RUM (Simon Willnauer) so mmapped files don't need to be paged in/out all the time, and finally: buy SSDs.
Happy mmapping!
And just the other day I was using mmapdirectory on a 64bit jvm, trying hard to set the highest heap size possible, reducing available ram for the disk cache. Stupid me.
ReplyDeleteThanks for this real eye opener!
Would also be interest to learn about any potential mmap cons. I assume ACID is fully kept for write OPs? Thanks.
Gill, MMapDirectory in lucene uses MMaps only for reading not for writing so there are no consequences along those lines. Additionally Lucene never modifies committed files so you won't have any corruptions due to the fact you are using MMap.
Delete@Uwe: you really quoted me on the RUM thing didn't you! :) - good blog and needed I don't need to write answers to this anymore on the list but just point folks here!
One additional huge problem I had with mmap on a 32bit system (within a different app, not lucene) was that the system gots slow on strange parts of the code when the available memory got lower. debugging that was horrible :)
ReplyDeleteQuestions:
What if my index completely fits into RAM (say only 1 or 2 GB) and I need 100% performance. Wouldn't it then better to use a RAMDir?
And to avoid concurrency problems with RAMDirectory - wouldn't it be possible to implement a different one via off-heap direct-memory (not mmap)?
There is an issue for that. RAMDirectory has the other bug, that it allocates millions of byte[1024], because thats the block size. RAMDirectory is made solely for tests, not for production. I have a patch for RAMDirectory to use larger block sizes in Lucene 4.0, not yet committed (needs some love). It uses IOContext to estimate file size and changes the blocksize. Also for RAMDirectoryies that clones a FSDirectory, it allocates the whole file as one byte[] (or multiple 2 GB blocks, if larger). See https://issues.apache.org/jira/browse/LUCENE-3659
DeleteHi Uwe,
ReplyDeleteI tried changing the JVM -Xmx setting from 15GB to 6GB for a 21GB footprint index. The perf numbers are identical pretty much. It's much more satisfying to see RES of the process at 4.8GB instead of the 18GB it was before, that and the OS cache is at 20GB instead of 8GB. That's all well and good, but I was hoping for some other measureable indication that this is in fact "Better". E.g. less CPU for the same throughput or something. Any suggestions on where to look to see the tangible benefits?
Hi Mike,
DeleteI am wondering what you've set your vm.max_map_count size too for this 21GB index. Also, how would one go about calculating that?
Thanks in advance,
Bob
Hi Uwe,
ReplyDeleteI was curious what this means for the solr documentCache? If this is all essentially loaded into memory upon retrieval is there much point in needing it -- other than perhaps desiring autowarming? The other caches seem more relevant for continued use, but documentCache seems redundant. Is that right/sort of right?
Hi Surfdog,
ReplyDeleteindeed the Solr documentCache is somehow obsolete with MMapDirectory. The problem with MMapDirectory here is, that the *decoding* of the stored fields file still needs to be done, which takes some time, on the other hand, stored fields are only loaded for search results, which is in most cases only 20 or like that. Just like Lucene TopDocs, which has no cache at all and is very fast in displaying something like 20 documents, I would disable this cache. I generally recommend that to my customers for Lucene code to not cache Document objects, unless they do some result-post-processing fetching thousands of search result document objects.
in addition: The Solr document cache is very old and was in my opinion mainly implemented to work around thread synchronization in FieldsReader (this means, in earlier Lucene versions, IndexReader.document() was synchronized), so the bottleneck was not IO, but synchronization. This is no longer the case (since 2.9, as far as I know).
ReplyDeleteHi Uwe,
ReplyDeleteThanks for this interesting article. Do you think that like MongoDB or MySQL, Solr can affected by the NUMA like explained on these articles : http://www.mongodb.org/display/DOCS/NUMA and http://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/ ?
Regards,
Hi Laurent,
ReplyDeleteThe Oracle JDK has some improvements in its garbage collector and memory allocation for NUMA architectures. If you recognize problems with NUMA, use -XX:+UseNUMA -XX:+UseParallelGC as JVM parameters. This also improves the garbage collector (so it distributes the allocated objects correctly to CPU local memory). But in practise, we have not seen MySQL-like problems. The reason for this is: In JAVA you never allocate a large block with tons of memory (> the node-local memory). The reason for this is, that the maximum size of memory, Java can allocate for a single object is 2 GiB (new byte[Integer.MAX_VALUE]). Also the JDK will use libnuma, to distribute the allocated blocks accoring to their requirements.
In addition, as described in the blog post: Never allocate too much heap memory using -Xmx to your java process, as this slows down your index, because the operating system has no space for caching files which is the most important thing for Lucene/Solr.
About use of MMapDirectory: MMap is outside the JVM memory and loading/releasing memory mapped files is handled different in terms of NUMA. MMapped files are swapped in/out by the Linux kernel and the cache space is maintained by the OS kernel, so it is not assigned to a NUMA node at all.
Hi Uwe,
ReplyDeleteLike you have mentioned that it's best to disable documentCache.
What about filterCache, fieldValueCache and queryResultCache. Wouldn't these get effected too if we reduce heap space?
Also during indexing if the heap space is low could it give me heap space errors during a merge?
@varunthaker: filterCache is cheap to maintain (it is only bitsets) and it helps for fq queries e.g. with common facets. In general a filterCache used for numeric ranges is mostly useless, so i would recommend to turn it on for fq's with facets, but when you do filtering on geographic or date/time ranges, pass the no-cache query parser option to fq. FieldCache is needed for sorting and cannot be turned off, but may get obsolete with the introduction of Lucene-4.0-DocValues fields to Solr's schema (not yet fully implemented). QueryResultCache is like FilterCache caching results, but for queries it also caches the score values, so a simple bitset is not enough. If you have very expensive queries that repeat quite often (like Dismax), you should use it.
ReplyDeleteHi Uwe,
ReplyDeleteThanks for explaining the various caches.
Indeed once DocValues get integrated into the schema using them for sorting and faceting.
One this I'm still not clear about it how to balance between allocating heap space for running search. I know you can't really put a formula to it but as far as my understanding goes, Lucene benefits from having more free memory with the os but Solr being an application benefits from having more heap space.
Why I'm so keen on this balance is I want to make sure I don't run out of memory when committing the index or if I have a query with multiple facets and sort on fields while maintaining good search performance.
Hi Uwe,
ReplyDeleteI'm linux support for some developers trying to implement lucene and make use of mmapdirectory. I'm trying to figure out exactly what I need to do to facilitate this for them. Are there any kernel tweaks or anything that I need to do on the system? It's a RHEL 5.6 platform. If you could point me to any documentation from a systems, rather than a developers perspective, it would be greatly appreciated.
Vielen Dank,
Jay Herbig
Hi Jay,
ReplyDeleteunfortunately, I am also on the developer perspective :-). But I can answer parts of your questions, as I am also involved in managing Lucene-based servers:
- There are no special kernel-settings needed, the default kernels in all Linux distributions should support mmap, as this is required by POSIX and the ld.so loader is also using it to map .so files into address space and share them between processes (in linux, all libraries are mmaped into the processes).
The problem are (as noted before) some restrictive settings with ulimit:
- Lucene in general needs a large number of open files, so you should in all cases raise the maximum open file count per process. On servers only running lucene apps and nothing more (which we recommend), the upper limit is just useless and should be raised to some maximum like 32768 open files (depends on kernel). If you don't want to raise it too high, use at a minimum 8192 - this is not really specific to mmap, applies all Lucene storage implementions. This setting is "ulimit -n"
- The important settings to raise to unlimited/maximum are: "ulimit -v" (virtual memory, must be unlimited, otherwise you cannot map the index. As my article says, this has nothing to do with physical RAM, its only the size of address space the app can occupy. The setting of virtual mem is only important on 32 bit systems, where one process could easily allocate the whole virtual 32 bit off address space, bringing the server down). On 64 bit this is unlikely to happen :-) Max memory size ("ulimit -m") should also be unlimited. Both settings are unlimited in most linux distribs like Ubuntu, Debian. I have no idea about Redhat or SUSE, at least I know that SUSE by default has set some limits on server platforms.
There may be other settings in ulimit (like maximum file size, but I don't think you would have any limits by default).
Finally: If yur indexes are *really* large (terabytes), you may need to raise the sysctl "vm.max_map_count", but that's all (see my explanation above).
In any case, if I get link to an article about "sys admin's settings", I will post it here.
Thanks Uwe, for sharing such valuable information.
ReplyDeleteAs you explained about JVM allocation size, what about CPU?
Solr/Lucene is CPU intensive. We see contineous CPU spike on Solr Slaves. Do you have any recommendation on the # of CPUs too?
Hi Uwe, thanks for sharing thoughts on mmap impl for linux 64 bits.
ReplyDeleteIs there any additional recommendation when using different hosts of appservers sharing indexes stored in NFS ? Only one appserver instance writes to index, the other instances only read.
Great article! But what if I really don't want to have any disk i/o in my application is the preferred way to solve this by using ramfs? And if I do, what is the preferred Directory to use? If I use MMapDirectory I will duplicate data in memory I guess, would it be better to use NIOFSDirectory in this case?
ReplyDeleteJohan: There are currently plans to create a new RAMDirectory like implementation that uses ByteBuffers, which can be on Java heap (ByteBuffer.allocate()) or off-heap (allocateDirect()). The code would be similar to MMapDirectory (which already uses a generic ByteBuffer interface). Only code for writing is missing in Lucene. If I have time, I will work on this. The problems with writing (and also RAMDirectory in general) are the fact that in older Lucene versions, we don't really know how big the files are. Because of This, while writing RAMDirectory allocates in blocks of 1024 byte... So Garbage collector has to handle millions of small byte[1024] if you have a large index in RAMDirectory. In Lucene 4.0, with IOContext, we can somehow estimate the size of the merged segments, so the new ByteBuffer-based RAMDirectory (can allocate bigger blocks instead of defaul 1024 bytes).
ReplyDeleteThe whole thing only makes sense for Indexes that are *never* written to disk. Otherwise, if it is on disk, MMapDirectory is the way to go. Copying from disk to RAM explicitly is stupid, see the blog post, because MMapDirectory does not waste additional RAM.
While your article is helpful in some aspects, it is trivially simplistic in others. Nothing is for "free". Regardless of how much virtual address space is available, the physical address space is limited.
ReplyDeleteYour many points about the inefficiency of the java heap are generally correct. Yes, it's true that memory-mapped files are more efficient for loading an index into physical memory. However, in other ways your praise of memory mapping the virtual address space is trivial and simplistic.
If the index is so large that there are very large amounts of virtual memory from the memory mapped files being loaded into physical memory, then this crowds out the physical memory in use by the app and all other apps on the system. In such cases, large amounts will then be frequently swapped out to the OS swap file. There is only so much physical memory available. Your trivial comment to "buy more RAM" in such cases is silly. Nobody wants to buy more RAM because one process is a memory hog. That silly comment applies just as well to using RAMDirectory. Why would anyone memory-map files at all if they could just "buy more RAM" and load the whole index into RAM. If RAM is unlimited then the memory map is pointless. The reason is that we don't want to buy more RAM whenever a process is a memory hog.
We are seeing a lucene app with 50 gb of virtual memory. The O/S is running out of swap space, killing performance, because the vast virtual memory in use by Lucene is hogging the physical address space. We're actually hitting the limits on the swap file, which means we are swapping out way too much memory because of the lucene memory mapping.
It's true that using a different lucene directory mapping would be worse. But it's also true that the MMapDirectory is no panacea, and it has its limits. Virtual address space is not "for free". Unlimited use of virtual memory is not for free.
scf: If your machine is aggressively swapping out process memory in order to make room for memory mapping, you need to adjust your system. If you are using Linux, the keyword is "swappiness". Turning this way down should nullify everything you are ranting about.
ReplyDeleteNo, that's another simplistic answer. Swappiness does not solve the problem. Regardless of how much you tell the operating system to avoid swap, when a memory mapped file is requested, the operating system has no choice but to load it into physical RAM. Swappiness refers to situations of choice when the operating system may choose to cache into swap RAM that has remained unused for a while. It has no impact when your apache lucene is a memory hog.
DeleteGreat post! Thanks! I've always reserved a lot of memory for Solr!
ReplyDeleteHi, I have a issue here. My server had a crash ans now the solr is not getting started. It is giving this error : org.apache.lucene.index.IndexNotFoundException: no segments* file found in org.apache.lucene.store.MMapDirectory@C:\Program Files\Apache Software Foundation\Tomcat 7.0\india\data\index lockFactory=org.apache.lucene.store.NativeFSLockFactory@72ba007e
ReplyDeleteCasically it has mapped the index directory in the viryual memory and accesing it from there. How can i delete this virtual memory casche so that it does not look at the file path mentioned.
Hi rocky,
ReplyDeletethis has nothing to do with virtual memory. You index was just corrupted by the crash. The virtual memory is freed asap when the process dies.
Hi Uwe,
ReplyDeletereally interesting blog !
But I have one thing to ask you ...
Now in Solr the default directory is the "NRTCachingDirectory" that relies on the "StandardDirectoryFactory" .
Do you know any detail ?
What are the differences between the MMap approach and this new one ?
I suppose the new directory implementation is better ?
StandardDirectoryFactory by default uses MMapDirectory, if a 64 bit system is detected. NRTCachingDirectory therefore uses MMapDirectory as the backing perm store. The reason is FSDirectory.open() which returns MMapDirectory on those platforms.
ReplyDeleteIn gerenal this should be configureable, means NRTCachingDirectory should be configureable to take another DirectoryFactory as delegate.
About the difference: NRTCachingDirectory is just a wrapper around another directoy (in your case MMap). The idea here is to improve the NRT case, where you don't always commit your indexed data but reopen the IndexReader quite often to see changes asap. Once you commit, the data is written to disk. This dir just caches the small amounts of data before they are written to disk on commit. This directory is not really faster than MMap on reading (a little bit it is - see above in blog post, because the Java overhead ByteBuffer vs. byte[]), but makes IO on the filesystem much faster, because the indexed data is not written to disk asap (only on commit or if caching buffer is full).
ReplyDeleteUwe , thank you very much for the quick and precise answer :)
ReplyDeleteOnly few things :
" This dir just caches the small amounts of data before they are written to disk on commit " -> in the NRT scenario we are talking about the fact that this implementation caches the documents produced by a soft commit until an Hard Commit happens?
"(only on commit or if caching buffer is full)" -> also in this phrase you are referring to the docs between a Soft and an hard Commit ?
If i understood well the Real Time Scenario it works like this :
We have the RamBuffer memory that accumulates documents, as soon as a SoftCommit is triggered this RamBuffer became free, a new Searcher is opened and the docs are moved to the Disk Cache of the NRTCachingDirectory. As soon as an hard commit is triggered the Disk Cache of the NRTCachingDirectory became free and the index is persisted on disk.
Am I Correct ?
Thank you in advance
"in the NRT scenario we are talking about the fact that this implementation caches the documents produced by a soft commit until an Hard Commit happens?" -> yes!
ReplyDeleteOf course if the buffer is too small, it will write to disk before the hard commit. But a commit still does not happen. The whole idea is just to delay writes as long as possible.
"If i understood well the Real Time Scenario it works like this" -> yes!
Thank you very much Uwe !
DeletePerfectly clear
Hi Uwe, I was going in deep more, because I want to have Clear at most the architecture :)
DeleteI'm going to try to be as clear as possible, because in my opinion in my previous posts I made a mistake :
Near Real Time Scenario
First of all we have the Ram Buffer.
The Ram Buffer will ingest documents until it is full or an hard commit happens. In that case the Ram Buffer is freed.
When the RamBuffer is full, the index is flushed to the directory but no open Searcher happens .
When a Soft commit happens we :
- open a new Searcher
- invalidate all high level caches ( eventually no per segment caches as for sorted fields or function queries)
- NO flush to the Solr Directory( this is the point, the RAMBuffer remains ? where is located the memory index for the Soft Commit ? In my opinion, in the RAMBuffer and we don't send anything to the Solr Directory )
When an Hard Commit Happens:
- the index segment in memory is flushed to the Solr Directory.
- the RAMBuffer is freed
- eventually based on the openSearcher, we open a new Searcher
After we have flushed our Index to our Directory we close a segment file and we are ready to proceed dependending on the Solr Directory implementation:
NrtCachingDirectory host small files in cache until is possibile and then finally fsync the files in cache to the Disk.
Sorry to bother you a lot, but I want to perfectly understand all the process :)
Cheers
Hi Uwe , If i understand correctly during lucene segment merges, it should read few segments and merges as one segment. In this case a read operation happening on index right ? According to lucene docs , MMapDirectory uses memory-mapped IO when reading. If so lucene segment merges will happen on jvm heap memory or out-side jvm memory ?
ReplyDeleteHi Anantha,
ReplyDeletemerges will use both types of memory: Because merges is not just copying data, while merging, the term dictionary and postings lists have to be rebuilt. E.g., Lucene will build a new FST for the term dictionaryand much more. So merging will need JVM heap and cpu resources, too.
Hi Uwe. When the end of merging occurs at the end of my full import of a 12G index I see 12G+ of actual RES in use, which I assume is for writing the final (single) *.fdt file. The bigger the index gets, the more RES is being used for the merge (to the detriment of other processes on the server which are being swapped out). At some point it seems there won't be enough. Is this unavoidable - do I have to buy as much RAM as the size of my index ?
ReplyDelete(this is solr 3.4 on a jvm with 1g heap on 64-bit linux)
Hi cos inman,
ReplyDeleteare you sure that you use MMapDirectory. This looks more like NIOFSDirectory:
Earlier Lucene versions had a bug that it used quite large I/O buffers when reading stuff like norms. Norms were read as one large chunk. When using NIOFSDirectory, this caused that the JVM internally allocated a direct byte buffer of the requested size (which was pooled, but one you requested a large read, the pool had this large buffer). SimpleFSDirectory had a similar issue, but it just malloced the read buffer and freed it afterwards.
This was fixed in Lucene 4.5: https://issues.apache.org/jira/browse/LUCENE-5164
Hi Uwe, Thank for the informative article. I am running lucene queries against two identical indexes one stored on Network File storage (SAN) and other on local disk. I am measuing the search respone times by running tests against local index followed by index on NFS.Surpriseingly I am getting better response times with NFS compared to local storage (which supposed to be faster). Could this be due to mmap done during test 1 (with NFS index)? How can I clear the mmap (caching) created by test1 so that I can start run fresh test against local index.
ReplyDeleteBTW I am running this against Solaris 10 and 64-bit Java 1.7 update 25 , Lucene 4.2.1
Hi Vijay,
ReplyDeleteis this NFS file system or just a SAN server providing a virtual disk like iSCSI?
Hi Uwe, this is NFS file system .
ReplyDeleteHi Uwe,
ReplyDeleteThank you for the great article. Finally we are seeing great improvement once we switch to 64-bit java and MMapDirectory. Our Test run (multiple requests) used to take 26 minutes on32-bit and is reduced to 10 minutes on 64-bit java.
We load stored documents from lucene and pass the documents to a third party libray (closed source) for further processing. The third party library is memory intensive and it needs around 10GB of heap memory for our load. We have a cap of 16GB system memory available and our index is of 8GB in size so that means only 6GB is available for fscache.I would like to hear your views on this kind of configuration.
Hi Vijay,
ReplyDeletethe only answer I can give: buy more RUM(tm)! (as Simon Willnauer says). In fact the configuration is fine, but the response times might not be ideal, because there is now more disk I/O involved. I would try to reduce the heap space as much as possible. Another approach is to make the 3rd party processing on another machine? (if its e.g., Apache TIKA, you could use the TIKA RPC server to parse the documents and get the plain text out of them).
About the NFS: It could be that the NFS client is doing additional caching (more aggresive caching than local disks), and this cache can better be used by mmap. On the other hand, you should in any case clear your disk caches or reboot the machine between the tests. If you first do extensive NFS tests and then move to local disks, the more NFS cache might keep the pages more aggressively in RAM, so the local disk does not use the disk cache in the same way?
You can clear the whole disk cache before your tests to always start with same config (on linux): echo 3 > /proc/sys/vm/drop_caches [3 means *all* caches], see https://www.kernel.org/doc/Documentation/sysctl/vm.txt for more info.
I am running around eight solr servers (version 3.5) instances behind a Load Balancer. All servers are identical and the LB is weighted by number connections. The servers have around 4M documents and receive a constant flow of queries. When the solr server starts, it works fine. But after some time running, it starts to take longer respond to queries, and the server I/O goes crazy to 100%. Why this is happening?
ReplyDeleteI tried to change both the vm.max_map_count and the -Xmx parameters, but the problem persists...
http://stackoverflow.com/questions/28110242/solr-i-o-increases-over-time
Have seen our physical memory full (99%) and have swap disabled on our cassandra+SOLR JVM instance although actually allocated memory is 10% heap. What are the consequences then? What happens when we start new processes that need additional memory but the physical memory is full?
ReplyDeleteIs it a good idea to control OS memory space usage or filesystem caching usages?
DeleteHi Radha,
Deletethanks for the question!
In fact the memory usage is quite normal. If you type "free -h" on your linux command line, you will see two lines (the first one showing 100% memory usage), but the second line "-/+ buffers/cache" shows the realy "wired" usage (so really allocated memory). The remaining stuff is used for cache.
As described in the article the remaining memory is used for file system cache - and lucene accesses the file system cache dircetly, so it has best performance. A server that uses 100% of all its memory for caching purposes is a good configured one, otherwise you would not use the resources at all.
Now to your question: If you start another process that needs additional RAM, the kernel will drop the claimed cache space asap and make memory free for the new process. This is cheap, because the file system cache, mmaped to virtual address space, is used read-only by lucene, so it can be freed without syncing to disk.
After the new process is started, of course the part of the index is no longer available in file system cache. So on the next access the standard paging algorithm of the kernel will take care to free older caches and page-in required index parts.
In fact you disabled swapping, but that does not mean that the operatring system will no longer page. mmapped files will be pages in and out as needed. Just a swap file is no longer used. But the Lucene index can be seen like a swap file - which is paged in and out as needed. More RAM helps, so ideally the whole index is available in pyhsical RAM, so paging is not needed... :-)
For Lucene, please don't control caching usage (e.g. via ulimit). This just causes errors like "mmap failed".
I am running SOLR server ( solr version 4.10.3 & java version 1.7.0_67).
ReplyDeleteServer Details : Amazon aws c3.xlarge server (7.5 GB RAM, 4vCPU). Linux Ubuntu 14.04.1 LTS and installed Bitnami Apache Solr 4.10.3-0. Allocated JVM memory minimum 1GB and maximun 2GB. The server have around 650 million dcoucment indexed (Indexed field count is 37 & stored field count is 10).
When the solr server starts, it works fine. But after some time running (constant flow of select queries (SpatialSearch)), it takes longer to respond the queires and physical memory goes to full (99.5%) and got the java heap space error.
Why physical memory is full after completing the queries ? Can you please suggest me configuration details for SpatialSearch.
This comment has been removed by the author.
ReplyDeleteI must say, this is wonderful explanation.
ReplyDeleteThank you Uwe Schindler.
Awesome explanation
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteHi I have a system requirement where i want entire index in RAM. I have more than enough RAM so size is not an issue. As you have mentioned in this blog
ReplyDelete"
Java and the O/S optionally provide the option to try loading the whole file into RAM (if enough is available), but Lucene does not use that option (we may add this possibility in a later version)
"
I was wondering if this feature is already available in Lucene? Also, can you please suggest any other alternative which I can test to achieve the complete index in RAM?
Hi,
Deleterecent version sof Lucene have a new method setPreload(boolean) on MMapDirectory. If you set it to true, it will call MappedByteBuffers's load method: [https://lucene.apache.org/core/5_5_0/core/org/apache/lucene/store/MMapDirectory.html#setPreload(boolean)] But this does not guarantee that the index is in physical memory, it just reads the file page for page after opening to enforce a page-fault, so it will be in filesystem cache. But the OS kernel is still open to swap out and free tha cache if needed (e.g. when another large file is openend and cache is full).
With modern operating systems there is no way at all to enforce something in physical memory.
Thanks this post is really useful.
ReplyDeleteWhat are the pros and cons of increasing vm.max_map_count from 64k to 256k?
Does 64k vm.max_map_count imply --> 64k addresses * 64kb page size = upto 4GB of lucene index data can be accommodated on FS cache? And if i exceed 4GB, i will need to page out some of the older accessed index data?
How does this limit result in OOM
Hi Unknown,
ReplyDeletethe page size has nothing to do with the max_map_count. It is the number of mappings that are allocated. Lucene's MMapDirectory maps in portions of up to 1 GiB. The number of mappings is therefor dependent on the number of segments (number of files in the index directory) and their size. A typical index with like 40 files in index directory, all of them smaller than 1 GiB needs 40 mappings. If the index is larger, has 40 files and most segments have like 20 Gigabytes, then it could take up to 800 mappings.
The reson why Elasticsearch people recommend to raise max_map_count is because of their customer structure. Most Logstash users have Elasticsearch clouds with like 10,000 indexes each possibly very large, so the number of mapping could get a limiting factor.
I'd suggest to not change the default setting, unless you get IOExceptions about "map failed" (please note: it will not result in OOMs with recent Lucene versions as this is handled internally!!!!)
The paging of the OS has nothing to do with the mapped file count. The max_map_count is just a limit on how many mappings in total can be used. A mapping needs one chunk of up to 1 GiB that is mmapped. Paging in the OS happens on a much lower level, it will swap any part according to the page size of those chunks independently: chunk != page size
Thanks Uwe! - i understand things better now.
ReplyDeleteYou might also review Jörg Prante's blog post: http://jprante.github.io/lessons/2012/07/26/Mmap-with-Lucene.html
ReplyDeleteHello Uwe
ReplyDeleteI'm using SolrCloud 7.7, with 3 machines, 3 shards and 3 replicas. I kept everything as default except heep size and auto soft commit, the performance is good but the memory utilization always high over 94%. is there any settings to reduce the memory utilization and keep the performance good?
Thanks
Issa
Hi Uwe,
ReplyDeleteCurrently i'm Mmap 1.5 GB of lucene index, i noticed virtual memory size gone up from 14GB to 23GB(that's fine this size includes the size of swapout pages in hard-drive). But i'm witnessing increase in RSS(resident-size) size from 8GB to 12GB if we use MMAP. Any suggestion to reduce RSS usage without compensating performance.
ReplyDeleteThat is a very good tip especially to those new to the blogosphere.
Short but very accurate info… Appreciate your sharing this one. A must read post.
My web site - 오피
(jk)
I'll add it to my bookmarks so I can visit it often! And I will share it with my acquaintances. And there is a lot of useful information on our website too, so please take a look and take a look. Then have a good day. ufabet1688
ReplyDeleteWir sind Ihr professioneller Partner in Sachen Grafikdesign, Social Media Marketing, Webseiten sowie Webshop Systeme. Dabei steht der Kontakt mit unseren Kunden im Vordergrund. Bei uns müssen Sie nicht lange warten – der direkte und persönliche Kontakt ist uns sehr wichtig. Werbeagentur Tirol
ReplyDeleteWir sammeln Empfehlungen von vielen vertrauenswürdigen Verlagen und Reiseexperten wie Lonely Planet, CN Traveler, CNN, The New York Times, Fodor’s, Frommer’s, The Guardian und anderen. wo übernachten in Washington D.C.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteMake sure you keep all of us up to date such as this. เว็บเล่นบาคาร่าที่คนเล่นเยอะที่สุด
ReplyDeleteHey friend, it is very well written article, thank you for the valuable and useful information you provide in this post. Keep up the good work! FYI, Pet Care adda
ReplyDeleteCredit card processing, why i am an atheist pdf,10 lines on Lawyer in English
super
ReplyDelete파워볼사이트 association still a chance. The possibility of the breakaway association has slowed down Europe's arrangement of Harrington's replacement.
Hi there, I found your blog via Google while searching for such kinda informative post and your post looks very interesting for me. agen togel
ReplyDeleteสิ่งที่ทำให้เกิดเกมบาคาร่าแล้วก็เหตุผลที่เกมเป็นที่นิยมมากมายในตอนนี้
ReplyDeleteอย่างที่พวกเราทราบกันดีอยู่แล้วว่าเดมแนวพนันเป็นเกมที่เล่นแล้วได้เงินจริงและก็หนึ่งในเกมแนวพนันที่ได้รับความนิยมมากมายๆก็คือ เกมไพ่บาคาร่า รวมทั้งแม้ในตอนนี้จะเข้ามาสู่สมัยของโลกอินเตอร์เน็ตและจากนั้นก็ตามกลับได้มาพบว่าเกมไพ่เกมนี้ยังคงเป็นที่นิยมมากมายอยู่เสมอดโดยที่ไม่มีวี่แววว่าความนิยมจะลดน้อยลงอะไร
ต้นเหตุของบาคาร่า
บาคาร่า มีที่มาจากเกมไพ่ด้านในบ่อนคาสิโนทั่วๆไป แต่ว่าคราวหลังบ่อนพนันกลับเป็นที่นิยมลดน้อยลงเพราะจะต้องใช้เงินลงทุนที่สูงไม่ว่าจะเป็นการเดินทางไปบ่อน ไปจนกระทั่งการเสี่ยงที่จำต้องพบเจอการเช็ดกทุจริตได้ ทำให้ในขณะนี้เกมไพ่เกมนี้ถูกทำให้อยู่ในลักษณะของเกมออนไลน์ที่ผู้เล่นสามารถเล่นเกมพอดีไหนก็ได้ตามอยากได้
คุณลักษณะเด่นของบาคาร่าออนไลน์
บาคาร่ามีจุดแข็งอยู่หลายประการที่ทำให้เกมเป็นเกมยอดนิยมมาตลอด ดังนี้
• เล่นง่าย ได้เงินไว
• มีวิธีการเอาชนะที่ไม่สลับซับซ้อนทำให้ผู้เล่นใหม่สามารถศึกษาและก็เล่นเกมได้ด้วยตัวเอง
• แม้ว่าจะเป็นการเล่นผ่านระบบออนไลน์แม้กระนั้นก็มีอินเทอร์เฟสเกมที่รู้เรื่องได้มากยาก ศึกษาวิธีการใช้ได้ด้วยตัวเอง
• ไม่จำเป็นที่จะต้องใช้วิธีสำหรับเพื่อการเล่นก็สามารถเอาชนะได้ แม้กระนั้นถ้าทราบแนวทางก็ถือว่าเป็นการเพิ่มจังหวะสำหรับเพื่อการเอาชนะเกมให้สูงนเพิ่มขึ้น
บาคาร่า
บาคาร่า เล่นแล้วไม่ถูกโกงอย่างแน่แท้ 100 เปอร์เซ็นต์
การฉ้อฉลเงินนั้นมองเห็นได้เป็นประจำในเกมสไตล์พนัน แม้กระนั้นถ้าหากคุณเล่นเกมผ่าน sagaming คุณจะไม่ต้องสัมผัสประสบการณ์อันชั่วร้ายพวกนั้นที่คุณไม่ได้อยากต้องการพบ โดยอย่างแรกแม้คุณเล่นเกมผ่านทางเว็บไซต์บาคาร่า จะก่อให้คุณได้รับความปลอดภัยจากเว็บแน่ๆ 100 เปอร์เซ็นต์รับรองด้วยระบบการดูแลเว็บประสิทธิภาพ
ยิ่งไปกว่านี้คุณยังสามารถเชื่อมั่นด้วยเอกสารสิทธิ์ก่อตั้งเว็บคาสิโนออนไลน์ที่ได้รับจากประเทศฟิลิปปินส์ sagaming จะไม่คดโกงผู้เล่นอย่างแน่แท้ ดังนี้ระบบการใช้แรงงานทั้งผองจะอยู่ในต้นแบบออนไลน์ให้ผู้เล่นสามารถวางใจได้มากยิ่งกว่าการใช้ระบบเงินสด
แล้วก็ด้วยเหตุผลต่างๆที่พวกเราได้กล่าวไปในข้างต้นก็เลยทำให้เกมไพ่เกมนี้ได้รับความนิยมอยู่เสมอ ไม่ว่าจะด้วยเหตุผลสำคัญๆอย่างเล่นง่าย เล่นแล้วได้เงินไว ไปจนกระทั่งเรื่องของเหตุผลย่อยๆอย่างการที่ตัวเกมเป็นอีกหนึ่งความคลาสสิกที่ทำให้เหล่านักพนันเลิกเล่นมิได้ก็นับว่าเป็นอีกเหตุผลหนึ่งที่ช่วยตอบปัญหาว่าเพราะเหตุใดเกมไพ่ที่ซ้ำจากจำเจเกมนี้ถึงเป็นที่นิยมมากมายในโลกอินเตอร์เน็ต
การฝาก-ถอน บาคาร่า อัตโนมัติบนเกมพนันออนไลน์ บาคาร่า
ReplyDeleteการร่วมเล่นเกมบาคาร่า พนันออนไลน์ ผู้เล่นจึงต้องควรฝากเงินเข้าระบบ USER ของผู้เล่นก่อน ที่จะเริ่มพนัน โดยกรรมวิธีการฝาก-ถอนปัจจุบันนี้สามารถทำเป็นง่าย สบาย สบาย ผ่านระบบออนไลน์ โดยที่ผู้เล่นสามารถฝากเงินเข้าผ่านระบบออนไลน์ได้เลย หรือถ้าหากว่าผลการพนันออกมาว่าผู้เล่นชนะการเดิมพัน ผู้เล่นก็สามารถรอรับเงินรางวัลเข้าระบบ USER ของเพศผู้เล่นเองได้เลย
ขั้นตอนการฝาก-ถอนอัตโนมัติ
ถึงแม้ผู้เล่นเป็นผู้เล่น บาคาร่า มือใหม่ที่สงสัยเกี่ยวกับกรรมวิธีฝากเงินก่อนเริ่มพนัน ผู้เล่นสามารถประพฤติตามขั้นตอนเหล่านี้ได้เลย เพื่อจะได้สบาย แล้วก็เงินทุนของนักพนันที่จะฝากเข้าระบบ ก็สามารถที่จะเข้าระบบ USER ของผู้เลนได้เลย ต่อจากนั้นผู้เล่นสามารถเริ่มนำเงินที่ทุนที่ฝากนั้นพนันได้เลย
1. เลือก “ฝากเงินออโต้”
ขั้นที่หนึ่งผู้เล่นควรต้องเข้าระบบบาคาร่า ก่อน ถัดจากนั้นให้เลือก “ฝากเงินออโต้” ระบบนี้จะเป็นการฝากเงินเข้าระบบของเพศผู้เล่นอัตโนมัติ
2. เลือก “คัดลอกเลขลำดับบัญชี”
ถัดไปให้ผู้เล่น คัดลอกลำดับที่บัญชีของเพศผู้เล่นเอง เพื่อสบายต่อการฝากเงิน ผ่านระบบอัตโนมัติ
3. ใส่เลขบัญชี ที่คัดลอกไว้ พร้อมจำนวนเงินที่ฝาก โอนแล้วเข้าเกมอัตโนมัติ
ถึงแม้คัดลอกเลขบัญชีแล้ว ผู้เล่นก็จำเป็นที่จะต้องใส่จำนวนเงินทุนที่ผู้เล่นต้องการจะเพิ่มเข้าระบบของตนเองว่าจะเพิ่มเงินเข้ามากมากแค่ไหน ให้ผู้เล่นกรอกเลขเงินให้ถูกและแน่ชัด ภายหลังที่ผู้เล่นที่กรอกรทุกสิ่งทุกอย่างครบแล้วจำนวนเงินที่ผู้เล่นกรอกก็จะเข้าระบบ แล้วหลังจากนั้นก็เข้าเกมพนันที่ตนเองพึงพอใจเลย รวมถึงสามารถนำเงินทุนนั้นลงพนันได้เลย
4. ถอนเงิน
ถ้าเริ่มพนันแล้ว ผลการพนันออกมาว่าผู้เล่นชนะผลการพนันให้ผู้เล่นคอยรับรางวัลเข้าระบบของผู้เล่นได้เลย ต่อมาแล้วผู้เล่นก็สามารถ กดเลือก “ถอนเงิน” แล้วนักพนันก็สามารถถอนเงินออกมาได้เลย สามารถถอนเงินออกมาใช้ได้จริง และก็เร็ว
จากที่ได้กล่าวถึงไปแล้ว เป็นผู้เล่นบาคาร่า จำเป็นต้องทำการสมัครสมาชิกก่อนเพื่อเป็นพวกเอาไว้เข้าระบบไว้เล่นเกมพนันออนไลน์ ถัดจากนั้นแล้วผู้เล่นก็ยังสามารถฝากเงินเข้าไปในระบบ เพื่อจะนำเงินทุนนี้ไปเริ่มพนันในเกมที่ผู้เล่นพึงพอใจ หากผู้เล่นได้ทำการฝากเงิน แล้วหลังจากนั้นก็เริ่มพนันแล้ว ถ้าหากผลการพนันออกมาว่าชนะผู้เล่นก็ยังสามารถรับเงินรางวัลจากการเดิมพันได้เลย โดยที่เงินจะเข้าในระบบ USER ของนักเล่นการพนันเลย
Bookie in Jordan 15 Casino Tours Online
ReplyDeleteDiscover and reach the best authentic air jordan 13 shoes Online gambling sites for any kind of good retro jordans occasion. 출장마사지 Bookie-in-Jordan, 15 buy air jordan 10 retro Casino Tours - Discover the best gambling sites for งานออนไลน์ Any kind of
Brains are awesome. I wish everybody would have one! UFA800
ReplyDeleteufabet AUTO คุณสามารถเดิมพันในเกม ไซต์การพนันออนไลน์ ไอ โปร เบ ท 168 มีแอพลงทะเบียนง่าย ๆ เพียงไม่กี่ขั้นตอนกับทีม wallet.slot th ที่พร้อมให้บริการเสมอและเกมออนไลน์อื่น ๆ อีกมากมายเช่นการพนันออนไลน์เกมลอตเตอรี เกมอย่างบาคาร่าและรูเล็ต ไฮโล น้ำเต้า ปู ปลาออนไลน์ – เกมโปรดของฉัน รูปแบบของเกมมีความคล้ายคลึงกันอย่างไร? มีกติกาที่ใกล้เคียงไฮโลมากด้วยการเล่นอูฟาแทงน้ำเต้า ข้อแตกต่างเพียงอย่างเดียวคือการเดิมพันและสัญลักษณ์ที่มีไฮโลหลายตัว โดยทั่วไป หลายคนชอบเล่นเคซี่ย์กุ้งฟิชเพราะว่ามันยากและเข้าใจง่ายกว่าซิกโบ สำหรับผู้ที่อยากเล่นทางเข้า UFA LION wallet slot Click Here
ReplyDeleteDuring the post or exchange of information, you may be able to expose your business. Look for blogs in your niche that have an extensive membership and traffic. Use this method to channel some of the traffic from the blog or forum into your website. add more
ReplyDeleteโปรโมชั่นทำเงินJoker ยกระดับการทำเงินที่มีเงินรางวัลรออยู่อย่างมากมาย กับฟังก์ชั่นสล็อตเครดิตฟรี จากค่าย สล็อตโจ๊กเกอร์ ที่เข้ารับได้ผ่านทางเว็ป http://www.jokerslot.ninja/ เพียงมีข้อกำหนดการทำเงินเพียงไม่กี่ข้อก็สามารถเข้าทำเงินแบบไม่มีขีดจำกัด.
ReplyDeleteCommon sense is like deodorant. The people who need it most never use it. OVERBET99
ReplyDeleteรู้จักเขา รู้จักเรา รู้วิธีเล่นเกมสล็อตต่างๆ ก่อน เราสามารถทำกำไรให้ตัวเองได้ง่ายๆ ใครที่กำลังมองหาเกมหรือต้องการทราบข้อมูลเพิ่มเติมเกี่ยวกับเกมสล็อตหรือฟีเจอร์ต่าง ๆ ในเกมเชิญขึ้นมาทางนี้ ทดลองเล่นสล็อต pgslot โปรดเข้าร่วม ลองเล่นเกมดู เราที่ PG168 Games ต้องการให้ผู้เล่นรู้จักเกมประเภทต่างๆ มากขึ้น
ReplyDeleteI think this is the best article that I never seen before and I personally think it give me many profit
ReplyDeleteยูฟ่าเบทล็อกอินบนมือถือ
Real Novelty Documents is a company where all the needs and requirements of the clients are taken into consideration without fail. From our company, you can now easily buy real fake passport online in a convenient manner.
ReplyDeleteVenturs Metals is an interesting destination for people who look forward to becoming rid of tyre scrap scattered all over their place. We are the prominent tyre scrap Exporters who fulfill the needs and requirements of people from all around the world. We take away all the unused tyres along with us in a short period possible.
ReplyDeleteRoyalty Novelty Docs es una agencia estimada para comprar números de seguridad social en línea a un costo moderado. Estamos trabajando en esta industria durante un período prolongado y hemos ganado suficiente experiencia. Contamos con los expertos en TI que le permitirán obtener un número de seguro social en línea de manera viable.
ReplyDeletehttps://royaltynoveltydocs.org/tarjeta-de-seguro-social/
I hope you write more articles like this. I'm your biggest fan.เว็บข่าวบอล
ReplyDelete
ReplyDeleteBei uns erhalten Sie Backlink Pakete für eine erfolgreiche SEO. Ein Backlink ist ein Rückverweis (englisch: Backlink) bezeichnet einen Link, der von einer anderen Website auf die eigene Seite führt. Backlinks sind ein entscheidender Erfolgsfaktor für eine gute Position in Suchmaschinenergebnissen (search engine result pages; SERPS). dofollow backlinks
ReplyDelete3-MMC oder 3-Methylmethcathinon ist ein Molekül der Klasse der substituierten Cathinone. Cathinone sind eine Unterkategorie von Amphetaminen, die die grundlegende Amphetaminstruktur eines Phenylrings teilen, der über eine Ethylkette und eine zusätzliche Methylsubstitution an Rα mit einer Aminogruppe (NH2) verbunden ist. 3-MMC-Pulver zum Online-Verkauf
Thanks for sharing a wonderful article.
ReplyDeletebest truck accident attorney
Your blog is really good and interesting. The operating system tries to optimize disk accesses, so it caches already all disk I/O in physical memory. We copy all these cache contents into our own virtual address space bankruptcy lawyers virginia beach, consuming horrible amounts of physical memory. Keep sharing more useful blogs...
ReplyDeleteOne of best article any one want legal support for you kindly visit our page thanks. Reckless Driving Halifax VA Lawyer
ReplyDeleteYour blogs are really good and interesting. It is very great and informative. separation agreement in virginia that Lucene/Solar can work with much better performance than before. Common misinformation about the background of this change causes suboptimal installations of this great search engine everywhere. I got a lots of useful information in your blog. Keeps sharing more useful blogs..
ReplyDeleteYour blog post is outstanding! The content is incredibly insightful and thoroughly researched. The author's ability to present information in a clear and engaging manner is truly commendable. The practical examples and actionable tips provided are not only valuable but also easily applicable. This post has definitely expanded my knowledge on the topic and left me hungry for more. Keep up the fantastic work!
ReplyDeleteDistrito Nueva Jersey Protección Orden
Exodus Web3 Wallet
ReplyDeleteis a versatile and user-friendly solution designed to empower you in managing, storing, and trading various cryptocurrencies. In this comprehensive guide, we'll walk you through the features, benefits, and steps to get started with Exodus Wallet.
Amazing, Your blogs are really good and interesting. It is very great and informative. I got a lots of useful information in your blogs. Common misinformation about the background of this change causes suboptimal installations of this great search engine everywhere abogados de accidentes. Keeps sharing more useful information in your blogs..
ReplyDeleteNice Article, "Don't be afraid" is a phrase we've all heard at some point in our lives, but its meaning is far from simple. We'll unravel the layers of fear, from the biological responses that keep us safe to the emotional challenges that hold us back. Understanding the various aspects of fear is crucial for personal development and well-being.
ReplyDeleteabogados de bancarrota de virginia beach virginia
Optimize performance on 64-bit platforms by leveraging Lucene’s MMapDirectory— a strategic choice for enhanced efficiency in data storage and retrieval. Embracing this recommendation ensures a seamless experience, harnessing the full potential of Lucene for robust and scalable applications. ||New Jersey Careless Driving Statute||Monmouth County Reckless Driving Attorney
ReplyDeletemisunderstandings are part of the human experience. By embracing clarity and understanding, we can navigate challenges with resilience and foster a more positive and informed perspective. Don't be afraid to question assumptions, seek clarification, and open yourself to a world of growth and connection.línea de tiempo de divorcio no disputado de virginia
ReplyDeletenueva jersey ley de divorcio sin culpa
oficina de quiebras cerca de mí
Make sure to replace "/path/to/index" with the actual path to your Lucene index directory. This code assumes that you have the Lucene library added to your project. dump truck accident
ReplyDeleteInsightful clarification on Lucene's MMapDirectory usage! Demystifying common misconceptions around virtual memory handling and dispelling misinformation. A must-read for Lucene users to optimize performance on 64-bit platforms
ReplyDeleteNew Jersey Reckless Driving
Amazing, Your blogs are really good and interesting. It is very great and informative. react native certification
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThe MMapDirectory class in Lucene is a powerful tool for high-performance indexing and search operations. By leveraging memory-mapped files, it significantly reduces I/O overhead and improves search performance, particularly for large indexes. This approach enables efficient access to the underlying data structures, making it an ideal choice for applications demanding fast query responses and scalability. Highly recommended for optimizing search throughput in production environments!
ReplyDeleteCost of Divorce in New York
The content provides a detailed explanation of Lucene's MMapDirectory, focusing on its benefits, common misconceptions, and configuration details for optimal performance on 64-bit platforms. It highlights the benefits of MMapDirectory, such as efficiency, performance, and efficient use of physical memory. However, it also addresses common misconceptions about memory consumption, index loading, and system reports. To improve clarity and flow, the content should include a brief introduction, break down sections into headings and subheadings, simplify technical terms, provide examples and illustrations, and be concise. abogado lesiones personales virginia
ReplyDelete
ReplyDeleteFactors such as the use of advanced technologies, additional services like genetic testing, and the experience of the medical team can also influence the cost of IVF treatment in Delhi. It is crucial for individuals to carefully review the costs associated with IVF treatment in Delhi and consider financial planning options such as insurance coverage, payment plans, or financing options.
By understanding the various components of IVF treatment costs in Delhi and discussing potential financial concerns with the clinic, individuals can make informed decisions about pursuing fertility treatment in the capital city.
I'm looking for a truly relaxing and indulgent experience. A female to male spa near me sounds like the perfect escape. Can you recommend any specific spas in the [city] area?
ReplyDeleteUncontested divorce forms in Virginia are essential documents for couples seeking to dissolve their marriage amicably and efficiently. This process is characterized by the absence of conflicts over the terms of the divorce, allowing for a quicker and less costly resolution. formularios de divorcio no disputados de virginia
ReplyDeleteStruggling with academic writing is a common challenge for students at all levels. Crafting a well-structured essay that meets academic standards can be daunting, especially when deadlines are tight. Professional Essay Help provides students with guidance on brainstorming ideas, structuring arguments, and refining drafts. From thesis development to proper referencing, expert support ensures that the final piece is clear, coherent, and compelling. Whether you need help with research, editing, or formatting, getting assistance can save time and boost grades. It also helps students improve their writing skills, giving them the confidence to handle future assignments independently.
ReplyDeleteI learned something from your blog. Continue sharing. Abogado de Divorcio Arlington | Arlington Abogado de Divorcio
ReplyDeleteGreat post! awesome post. I like this content. its very useful. Hope you will give more useful information. Condado de Orange Abogado de Familia
ReplyDeleteThe Generics Policeman Blog is a platform focused on discussing issues related to generic medications, healthcare policies, and pharmaceutical regulations. It aims to educate readers about the importance of generics in providing affordable healthcare options while advocating for transparency and quality in the pharmaceutical industry. The blog often features expert opinions, case studies, and updates on legislative changes affecting the generics market, promoting informed discussions among healthcare professionals and consumers.
ReplyDeletehanover county va reckless driving lawyer
reckless driving lawyer middlesex county
Thanks for your loveable content. I got informative blog. Keep sharing.Abogado Louisa
ReplyDeleteThat's a great content, exactly what I was looking for. Thank you and Abogado de Divorcio Arlington | Arlington Abogado de Divorcio continue doing a good job!
ReplyDeleteThe Generics Policeman Blog focuses on the legal and ethical issues surrounding generic drugs and their regulation. It explores topics like patent law, intellectual property, and the role of generic medications in healthcare. The blog also provides insights into the pharmaceutical industry, government policies, and public health impacts. Through analysis and commentary, it aims to inform readers about the challenges and debates in the generics market.
ReplyDeletedui checkpoints fairfax va
DUI Checkpoints in Fairfax VA
The Generics Policeman blog focuses on the challenges and policies surrounding generic medications. It offers expert commentary on issues such as market trends, regulations, and the healthcare industry's impact on the accessibility and affordability of generics. The blog also covers topics related to software development and technical aspects like default locales, charsets, and time zones, reflecting the author's broad range of interests. Readers can expect thoughtful analyses and insightful posts that serve as a resource for healthcare professionals, developers, and those interested in generic drug policies.
ReplyDeleteusing vehicle to promote prostitution
hillsboro sex crimes lawyer
This post does a great job addressing common fears and misunderstandings! It’s so easy to feel overwhelmed or hesitant when navigating something new, especially when there’s a lot of misinformation out there. I appreciate how clearly you broke down the myths and provided straightforward explanations. Knowledge really is power, and understanding the facts can make all the difference in helping people feel more confident. Thanks for taking the time to clarify things—it’s definitely helped ease my worries and probably many others’ too! reckless driving virginia 85 mph
ReplyDeleteviolate protective order virginia
Great! good work. Thanks for sharing.abogado de bancarrota del capítulo 7 cerca de mí
ReplyDeleteLeidest du unter Frust und Stress im BWL-Studium? Unsere Ghostwriter für Betriebswirtschaftslehre helfen dir bei allen schriftlichen Aufgaben! ghostwriter bwl
ReplyDeleteLeidest du unter Frust und Stress im BWL-Studium? Unsere Ghostwriter für Betriebswirtschaftslehre helfen dir bei allen schriftlichen Aufgaben! ghostwriting bwl
ReplyDeleteLassen Sie Ihre BWL Hausarbeit von Profis schreiben. Unser Service bietet maßgeschneiderte akademische Unterstützung, um Ihre Hausarbeit erfolgreich zu meistern. ghostwriter hausarbeit bwl
ReplyDeleteProfessionelle Unterstützung für Ihre BWL Bachelorarbeit Unser Ghostwriter Bachelorarbeit BWL erstellt wissenschaftlich fundierte Arbeiten mit hoher Qualität. ghostwriter bachelorarbeit bwl
ReplyDeleteBWL Seminararbeit schreiben lassen. Effizient und zuverlässig: Ihre BWL-Seminararbeit von Experten geschrieben. Kompetenz und Qualität. bwl seminararbeit schreiben lassen
ReplyDeleteBecause of the strictness of contributory negligence in Virginia, plaintiffs in Fairfax seeking compensation for injuries often rely on experienced personal injury attorneys. Lawyers can help gather evidence, argue against claims of contributory negligence, and aim to demonstrate that the plaintiff was not at fault, thus preserving their right to seek compensation. What is Contributory Negligence in Virginia Fairfax
ReplyDeleteI value the way you dispelled the myths and offered direct clarifications. Knowing the facts can make a big difference in boosting someone's confidence since knowledge truly is power. fairfax Robbery Lawyer A Fairfax robbery lawyer, based on average client experiences and characteristics of respectable local criminal defense lawyers. Because of the seriousness of the allegations, robbery calls for a criminal defense lawyer, especially one who has dealt with violent and property crimes in Virginia. Robberies involving the use of force, armed robbery, or robbery with a firearm are common defenses for clients of Fairfax robbery attorneys.
ReplyDeleteYour blogs are really good and interesting. It is very great and informative. Wireless networks will become a bit like computing in the online “cloud”, and in some senses will merge with it, using the same off-the-shelf hardware bankruptcy lawyer near me. I got a lots of useful information in your blog. Keeps sharing more useful blogs..
ReplyDeleteThe legal and moral concerns pertaining to generic medications and their control are the main topics of the Generics Policeman Blog. It looks at things like intellectual property, patent legislation, and the function of generic drugs in medicine. The site also discusses government regulations, the effects on public health, and the pharmaceutical sector. traffic attorney in manassas va A Manassas, Virginia traffic attorney with the necessary training and experience is crucial to the success of your case. Even though they may seem insignificant at the time, traffic infractions can have major repercussions, such as fines, points on your driving record, higher insurance costs, and in certain situations, jail time.
ReplyDeleteThe **MMapDirectory** from Lucene is revolutionary for 64-bit platforms' high-performance search. It provides lightning-fast access to index data by lowering disk I/O overhead through the use of memory-mapped I/O. It makes the most of the platform's memory capacity and works particularly well for huge indexes. An essential tool for large-scale, speed-sensitive search applications!The general law in the USA is a complex and evolving system rooted in both federal and state jurisdictions. It encompasses a wide range of legal principles, including constitutional, statutory, and case law. The system aims to balance individual rights with public order and safety. While it provides a framework for justice and legal processes, its complexity and variation across states can pose challenges. The ongoing development of laws reflects societal changes and strives to address contemporary issues, maintaining a dynamic legal landscape.
ReplyDeleteBankruptcies Lawyers Near Me
This article was truly enlightening! It's amazing how often misunderstandings can lead to unnecessary fear. Your clear explanations and factual approach help dispel myths and provide a much-needed sense of calm. Want to know about reckless driving lunenburg va lawyer click it.
ReplyDeleteLucene’s MMapDirectory is an invaluable tool for developers seeking high-performance search applications, particularly when dealing with large datasets or indexes. On 64-bit systems, it provides even greater advantages, allowing your application to access large index files with minimal overhead, leading to faster search responses and better scalability.
ReplyDeletemejores abogados de divorcio nueva jersey
bancarrota capítulo 7 cerca de mí
Odoo Inventory Management Software | Inventory System Canada
ReplyDeleteOdoo is the best inventory management software in Canada. Inventory software Features online inventory management, order fulfillment, and Traceability.
Odoo Inventory Management Software
It's good to read this cute post. It is interesting to read till the end. Keep sharing more good informative blogs.
ReplyDeleteabogado del capítulo 7 cerca de mí
Developers looking to create high-performance search applications may find Lucene's MMapDirectory to be a very useful tool, especially when working with big datasets or indexes. On 64-bit systems, it offers even more benefits, enabling your program to access massive index files with no overhead, improving scalability and search response times. 3rd dui in fairfax A third DUI conviction in Fairfax, Virginia, a skilled DUI lawyer who can handle the intricacies of such a grave accusation. Serious consequences, such as a lengthy license suspension, large fines, required alcohol education classes, and even jail time, may result with a third violation. a lawyer with extensive expertise handling repeat DUI cases. The way the attorney handled the unique difficulties of multiple DUI offenses is frequently highlighted by clients.
ReplyDeleteLucene’s MMapDirectory is an efficient file system directory implementation, optimized for 64-bit platforms... "As a lawyer, uphold the principles of justice, integrity, and confidentiality. Provide clear, accurate advice tailored to each client's unique needs.
ReplyDeletewhat is reckless driving in virginia
Thank you for sharing this insightful post! The way you’ve outlined the challenges and benefits of generics in the pharmaceutical industry is incredibly helpful. It's clear that ensuring accessibility without compromising quality is crucial. I look forward to reading more of your thoughtful analysis on this topic loudoun county divorce lawyers Great article! You’ve provided a comprehensive overview of the divorce process in Loudoun County, highlighting key aspects like property division and child custody. It’s so helpful to understand the legal complexities and how an experienced lawyer can make a difference. Thanks for sharing this valuable information.
ReplyDeleteThe review comments on the passage suggest restructuring to improve readability, introducing the benefits of MMapDirectory, and addressing common misconceptions. The paragraph should be broken into smaller sections, with a neutral tone to improve the professional feel. The structure should include an introduction, addressing common misconceptions, and a conclusion, reaffirming the benefits of MMapDirectory and providing tips to address common issues. fairfax wrongful death attorney Lawyers are bound by a code of ethics that requires them to maintain confidentiality, represent their clients to the best of their ability, and avoid conflicts of interest.
ReplyDeleteUsing Lucene’s MMapDirectory on 64-bit platforms can significantly improve performance. If you're dealing with legal issues related to traffic, an abogado tráfico Clarke VA can assist with your case.
ReplyDeleteGreat article! I appreciate the clear explanation of how to use Lucene's MMapDirectory on 64-bit systems. The performance benefits of memory-mapped files are well highlighted, and the practical tips make it easier to implement. Thanks for sharing this valuable insight!
ReplyDeletechild pornography defense attorney in virginia
indecent liberties with minor
I completely agree with the message of this article. It's so important not to be afraid to question what we hear and seek out the truth, especially when it comes to our health and well-being. The part about vaccines and autism really resonated with me because it's scary how misinformation can spread so easily. I also appreciate the clarification on healthy fats and carbs – it's all about balance and making informed choices. Thank you for shedding light on these common misunderstandings and empowering readers to stay curious and informed. Keep up the great work in debunking myths and promoting clarity!
ReplyDeletereckless driving lawyer rockbridge va
This was a fantastic deep dive into the topic. Thank you! Affordable Rugs
ReplyDeleteThank you for good blog rockville criminal lawyer An attorney that focusses on defending people or organisations accused of crimes in Rockville, Maryland, and the surrounding areas is known as a Rockville criminal lawyer. In instances ranging from small infractions to significant criminal charges, these criminal law specialists strive to defend their clients' rights and get the best results.
ReplyDeleteGreat article! Using MMapDirectory on 64-bit systems is a game-changer for Lucene performance, especially when dealing with large indexes. The ability to memory-map index files significantly reduces disk I/O overhead, leading to faster search speeds. However, it's also important to monitor memory usage, as excessive mapping can lead to address space exhaustion. Have you encountered any specific scenarios where MMapDirectory caused performance issues, and how did you handle them? Looking forward to your insights!
ReplyDeleteindecent liberties with minor
The Generics Policeman Blog focuses on pharmaceutical regulations, particularly concerning generic drugs. It provides insights on policies, approvals, and market trends in the pharmaceutical industry. The blog discusses legal, safety, and quality aspects of generic medications. It serves as a resource for professionals, regulators, and those interested in drug policies. Content includes analysis of industry developments and regulatory updates.
ReplyDeleteDrug Smuggling Lawyer
Drug Trafficking Lawyer
Loan Management Software | EMI collection software
ReplyDeletehttps://www.lendstack.in/loan-management-software-india
Streamline loan management and EMI collection with Lendstack's Loan Management Software. Simplify tracking, automate payments, and boost efficiency for lenders.
Great post! Clear explanations really help break down common misconceptions. If you're looking to start a business, visit Company Registration Consultants| Earnlogic for expert advice. Get Trademark Registration in Coimbatore
ReplyDeleteMit reduzierten Versandkosten von nur 18 € bietet RoyalDTF eine erschwingliche Lösung für Unternehmen, die Werbedrucke, Berufsbekleidung oder Merchandise-Produkte in hoher Qualität benötigen.
ReplyDeleteDTF Druck
There’s no better way to feel refreshed in Chiang Mai than with a time-honored Thai Massage. Let our guide show you where to go.
ReplyDeleteReady to go green with your knowledge? Explore the innovation behind this Cannabis Farm.
ReplyDeleteSeriös, diskret und kompetent. Denis Erdmann bringt nicht nur Erfahrung mit, sondern auch ein echtes Gespür für den Immobilienmarkt.
ReplyDeleteImmobilienmakler Straubing
Wer regelmäßig Texte erstellt, sollte Eskritor ausprobieren. Die gezielten Folgefragen helfen dabei, Inhalte wirklich auf den Punkt zu bringen.
ReplyDeleteKI Texter
Great read! I appreciate how clearly you break down complex regulatory topics surrounding generics. Your insights help demystify the process for those of us outside the legal or pharma industries. Looking forward to more updates and thoughtful analysis—this blog is a real gem for anyone interested in healthcare policy Coimbatore digital marketing expert Insightful post! Your expertise in digital marketing, especially tailored for the Coimbatore market, really shines through. The local strategies and real-world examples add great value. Thanks for sharing such practical tips—looking forward to more content that helps businesses grow with smart, localized digital solutions. Keep up the great work.
ReplyDeleteWenn man einen EMS-Dienstleister sucht, der nicht nur Standardlösungen anbietet, sondern maßgeschneiderte Konzepte umsetzt, ist man bei Dischereit an der richtigen Adresse. Besonders der Bereich SMD-Bestückung wirkt sehr kompetent aufgestellt.
ReplyDeleteEMS-Dienstleister
Ihr neuer Erste Hilfe Kasten wartet bei HLW-Shop.de! Praktisch, robust und ideal für unterwegs oder den festen Einsatz im Betrieb – jetzt entdecken!
ReplyDeleteerste hilfe kasten
Massage is more than a treatment—it’s a lifestyle. Step into that mindset with Massage Life and embrace the shift.
ReplyDelete
ReplyDeleteIch kann Gerber Immobilien in Hof wärmstens empfehlen! Besonders die individuelle Beratung und das ehrliche Engagement haben mich überzeugt. Eine Top-Adresse für alle, die eine Immobilie kaufen oder verkaufen möchten.
Immobilienmakler Hof
Great post! Thanks for sharing! One of the lesser-discussed advantages of Assignment Help is the improvement in research skills it can bring. These services often provide well-researched, properly cited examples that students can learn from. By reviewing such assignments, students gain a better understanding of how to find credible sources, cite them correctly, and synthesize information into coherent arguments. Over time, this improves their independent academic performance. When students are shown how to structure arguments and interpret data, they’re not just getting help—they’re gaining essential skills that benefit them throughout their academic careers and beyond.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteI'm glad you found the details helpful! As a top mobile game app development company we create addictive, high-performance games that keep players coming back. From concept to launch, our game developers bring your vision to life. Get started with your next mobile game today!
ReplyDeleteHi there, thanks for sharing the post. If anyone is looking for Uber clone app development , please contact us now!
ReplyDelete
ReplyDeleteIch bin begeistert, wie einfach man mit Magic Hour AI aus einem einzigen Bild ein lebendiges Video erzeugen kann – ideal für kreative Projekte und Social Media
ai video generator
I’m glad the information was helpful! If you’re searching for trusted app developers London UK, our team is here to bring your vision to life. We create user-friendly, high-performing apps that deliver real business results. Visit our website to find out more.
ReplyDeleteFantastically interesting post. It was an interesting read all the way through. Continue to publish high-quality content.
ReplyDeletenew york city drug lawyer
This post is still incredibly helpful for understanding Lucene’s MMapDirectory behavior on 64-bit systems—thanks for the clarity! On a different note, I recently came across this cool collection of Instagram Bio in Marathi
ReplyDelete—worth checking out if you like expressive profile ideas.
Great breakdown of memory mapping and performance implications—especially useful for optimizing large-scale indexing. If you're ever in the mood for something different, Insight Taiwan is a fantastic site to explore Taiwanese perspectives and culture.
ReplyDeleteEntdecken Sie unsere Auswahl an Kühlbox-Kühlgeräte für unterwegs – ideal für Boote, Camping oder lange Fahrten. Diese tragbaren Kühlschränke und Gefrierschränke bieten zuverlässige Kühlung, energieeffizienten Betrieb und robuste Bauweise. Egal ob frische Lebensmittel oder kalte Getränke – mit unseren Kühlbox-Kühlgeräte bleiben Ihre Vorräte stets gut gekühlt. Jetzt die passende Lösung für Ihren Bedarf auf ForBoat.eu finden!
ReplyDeleteDie Kombination aus systemischer Therapie, Hypnose und NLP ist in der Heilpraxis Göttmann besonders wirkungsvoll. Für Menschen mit Lebenskrisen oder traumatischen Erlebnissen eine echte Hilfe!
ReplyDeletePsychotherapie Darmstadt
Curious where locals and travelers go to relax? CNX MAP reveals the top massage destinations worth your time.
ReplyDeleteMit Treno.Finance kannst du Wallets und Portfolios einfach analysieren, vergleichen und managen – alles in einem Dashboard.
ReplyDeleteKrypto Risikoanalyse
Ich habe kürzlich die Seite von Dina Hegazi entdeckt – einem Medium in Berlin, das sowohl vor Ort in Schöneberg als auch online arbeitet. Besonders beeindruckt hat mich, wie präzise sie in ihren Readings Details vermittelt.
ReplyDeleteMedium Berlin
Make the right choice for your team’s living needs with our well-managed Worker Dormitory Singapore.
ReplyDeleteMit einem Fish Inn Gutschein können Sie köstliche Fischgerichte zum Vorteilspreis genießen. Ob frischer Lachs, knuspriges Fischfilet oder Meeresfrüchte – mit dem passenden Rabattcode sichern Sie sich Preisnachlässe auf Ihre Lieblingsspeisen. Die Gutscheine lassen sich online oder direkt vor Ort einlösen, je nach Anbieterbedingungen. Ideal für ein leckeres Abendessen, ein Familienessen oder auch zum Verschenken – der Fish Inn Gutschein bringt Qualität und Genuss zusammen. Schauen Sie regelmäßig nach aktuellen Angeboten, um keine Aktion zu verpassen!
ReplyDeleteFish Inn Gutschein
Thanks for sharing the post! It provides valuable insights. If anyone is looking to scale efficiently, partnering with an AI development company in Saudi Arabia can be a game-changer.
ReplyDeleteKnow more about what is power of attorney in india from the official website of legal blog hub - best legal blog in the world. This legal blog deliver the best information about several legal topics like how to apply bis certificate in india which helps you a lot.
ReplyDelete
ReplyDeleteZeugnisprofi bietet nicht nur eine Analyse, sondern auch fundiertes Wissen rund um Arbeitszeugnisse – sehr empfehlenswert für Bewerber und Arbeitnehmer.
arbeitszeugnis bewerten
The blog covers a range of topics—from pricing and quality comparisons to legal and ethical discussions. It aims to inform readers about the benefits and considerations of using generic options.
ReplyDeletealexandria va dui lawyer
Die Leistungen von VENALO zeigen, wie moderne Fahrzeugpflege aussehen kann. Neben Autos werden auch Wohnmobile und Motorräder behandelt, was gerade für Reisende und Vielfahrer ein großer Vorteil ist. Die Keramikversiegelungen sorgen nicht nur für intensiven Glanz, sondern auch für einen messbaren Werterhalt.
ReplyDeleteKeramikversiegelung
Tineco Nassreiniger sind wirklich beeindruckend, weil sie Saugen und Wischen gleichzeitig erledigen. Dadurch spart man nicht nur Zeit, sondern bekommt auch ein viel gründlicheres Ergebnis als mit herkömmlichen Geräten.
ReplyDeletetineco
Thanks for sharing such an insightful article. As someone working as an academic writer with Global Assignment Help Australia, I see many students struggle to balance essays, reports, and case studies while keeping up with deadlines. Quality assignment help often makes a real difference when it’s about structuring ideas or ensuring research depth.
ReplyDeleteAuf zeugnisprofi.com finden Arbeitnehmer und Arbeitgeber praxisnahe Unterstützung rund um das Thema Arbeitszeugnis. Neben einem leistungsstarken Zeugnisgenerator stehen auch professionelle Vorlagen und eine detaillierte Analysefunktion zur Verfügung. So lassen sich sowohl neue Arbeitszeugnisse rechtssicher schreiben als auch bestehende Zeugnisse inhaltlich korrekt interpretieren.
ReplyDeletearbeitszeugnis analyse
Thanks for the article, it is very helpful.⭐️⭐️🌈🌈✨✨
ReplyDeleteสล็อต
สล็อต เครดิตฟรี
สล็อตออนไลน์
สล็อต 66
สล็อต เว็บตรง
We’ll break down how MMapDirectory works, its benefits, and when it’s the right choice for your search infrastructure. Whether you're building a high-throughput search engine or just tuning performance, this is one optimization you shouldn't overlook.
ReplyDeleteindecent exposure laws
Auf hempli.de findet man THCA-Blüten, die nicht nur gut aussehen, sondern auch durch geprüfte Qualität überzeugen. Endlich ein Shop, dem man vertrauen kann.
ReplyDeleteTHCA Blüten kaufen
Mit der Online Druckerei von druckereimv erhältst du professionelle Ergebnisse, egal ob Flyer, Poster oder Verpackungen.
ReplyDeletemotorrad verkaufen ohne Risiko: Auf MotoBuy kannst du deine Daten eingeben und bekommst innerhalb von 48 Stunden eine realistische Preiseinschätzung. Besonders interessant für alle, die eine sichere und unkomplizierte Abwicklung bevorzugen.
ReplyDeleteFotobox Branding & CI-Lösungen von Fotobox NB sorgen dafür, dass jedes Foto Ihr Corporate Design widerspiegelt – von Logo, Farbwelt bis hin zu individuellen Rahmen. Ein starkes Erlebnis für Gäste, ein nachhaltiger Marketingeffekt für Ihr Unternehmen.
ReplyDeleteВ каталоге доступны клеммы для одножильных и многожильных проводов, проходные, многоразовые и универсальные модели.
ReplyDeleteThanks for this clear and practical explanation of using Lucene’s MMapDirectory on a 64‑bit JVM — it’s really helpful to understand how memory‑mapped I/O can improve search performance and reduce GC overhead for large indexes. Tips like tuning file system paging and JVM options make it easier to get the most out of Lucene in production. At Aatman Wellness, we value thoughtful optimization - whether in code or in life - because small improvements can lead to big gains in efficiency and wellbeing. Great info for developers looking to boost their search stack. Family Counselling Bangalore
ReplyDeleteI found the article you wrote to be very useful. I sincerely appreciate you sharing it. Your smile is our first focus at Aligning Dentistry, a state-of-the-art dental facility in Chennai. Our skilled dental team offers customized treatments in a safe, hygienic, and comfortable environment. With cutting-edge equipment and patient-focused care, we deliver everything from basic dental services to advanced procedures—making us the Best Dental Clinic in Chennai for quality and trust.
ReplyDeleteManagement Homework Help is available for university and college management students.
ReplyDeleteGerade im Raum Ludwigsburg ist ein vertrauensvoller Pflegedienst Ludwigsburg entscheidend. paz-pflege.com bietet umfassende ambulante Pflegeleistungen für unterschiedliche Bedürfnisse.
ReplyDeleteComo jugador, revisé parimatchcasino.cl y me pareció una plataforma clara y bien organizada. La navegación es sencilla, los menús visibles y todo carga rápido desde el móvil. Explorar las secciones disponibles resulta cómodo y directo, ofreciendo una experiencia práctica para moverse entre las distintas opciones sin complicaciones.
ReplyDeleteUnderstanding commands and drawing standards is essential for AutoCAD assignments. Initially, I found it hard to match academic requirements with technical execution. Through AutoCAD Assignment Help academic clarity, I learned how to structure drawings logically. I explored a helpful learning guide at AutoCAD Assignment Help that focused on skill development rather than shortcuts. My final work became cleaner and more accurate.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteWer Windows 11 kaufen möchte, findet bei myoem.de eine sichere Lösung.
ReplyDeleteThis article offers useful insights and helps provide a clearer understanding of the topic.
ReplyDeleteRead more at the link below.
⭐️⭐️🌈🌈✨✨
สล็อต
สล็อต เครดิตฟรี
สล็อตออนไลน์
สล็อต 66
สล็อต เว็บตรง
Great insights on using Lucene’s MMapDirectory for performance improvements! This approach can really help optimize search indexing efficiency. For those also focusing on visibility beyond technical search, check out my recommended resource on SEO services in Dubai to boost your site’s reach.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteDer ergonomische Laifen Rasierer von LaifenTech verbindet stilvolles Design mit exzellenter Schnittführung, sodass Rasieren einfacher, schneller und angenehmer wird. Ideal für Männer und Frauen, die Wert auf professionelle Pflege in den eigenen vier Wänden legen.
ReplyDeleteMit Hanfstreu von hanfeinstreu.de erhältst du eine Einstreu, die nicht nur funktional ist, sondern auch durch ihre natürliche Qualität überzeugt. Sie schafft eine trockene und bequeme Grundlage und unterstützt eine hygienische Haltung Tag für Tag.
ReplyDeleteThe blog thetaphi is the official blog of Theta Phi Alpha, a collegiate women’s fraternity in the United States. The blog shares updates about sisterhood activities, events, leadership, and community service initiatives. It also highlights member stories, achievements, and insights into fraternity life and values.
ReplyDeletebali yttc
baliyttc
Die Kombination aus einer wärmepumpe 12 kw und einem günstigen Heizstromtarif sorgt für maximale Effizienz. Auf heizstrom-kosten-vergleich.de finden Sie schnell heraus, welcher Anbieter zu Ihnen passt.
ReplyDeleteThanks for sharing the post! It provides valuable insights. If anyone is looking for a mobile app development company in Dubai, there are several expert agencies offering custom mobile app and AI development services to build scalable, secure, and user-friendly digital solutions that help businesses grow and improve customer engagement in the UAE market.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteManaging property in 2026 requires a clear understanding of shifting service costs. For homeowners, a leaning or dead tree isn't just an eyesore; it is a significant liability. A professional Tree Removal Cost Calculator serves as your first line of defense against overpaying. Most homeowners across the US find themselves paying between $400 and $1,200 for standard removals.
ReplyDeletehttps://treeremovalscostcalculator.com/